Speaking AI
8.12.2023
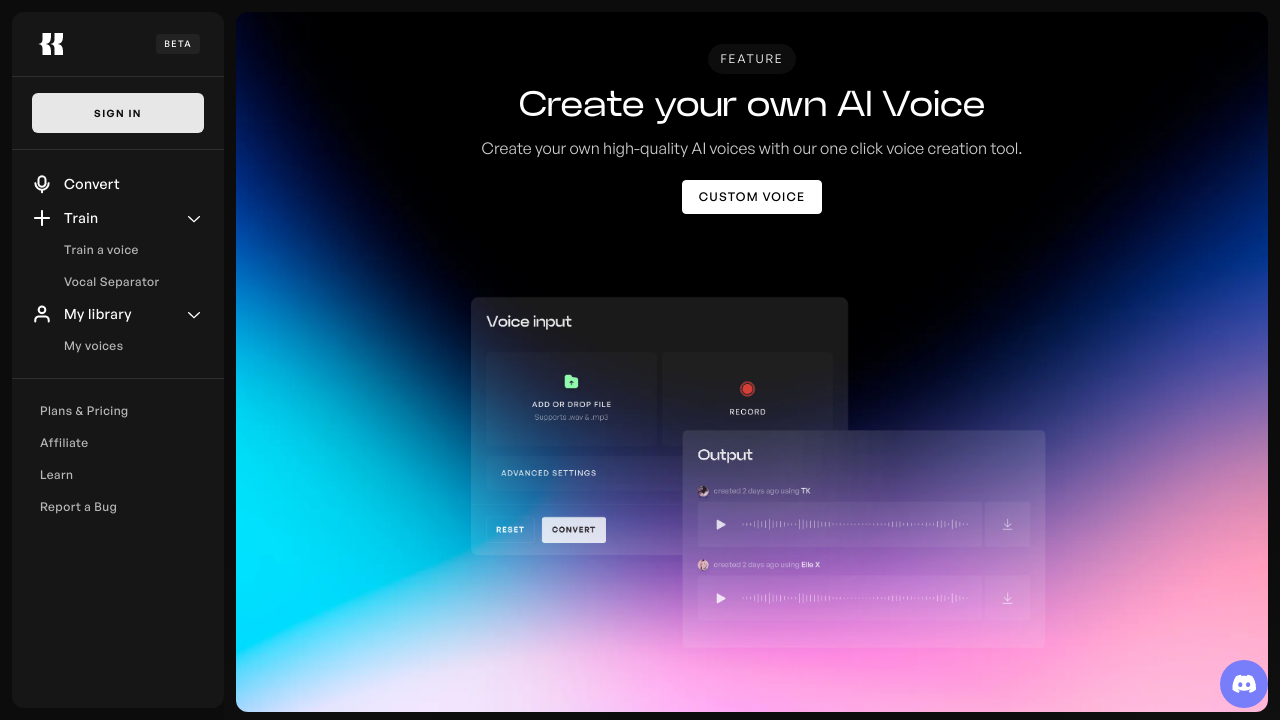
Die Beta-Version des Foundation Model in generativer Sprachtechnologie ermöglicht es, Ihren individuellen Tonfall mit nur drei Sekunden Audiomaterial zu erfassen. Sie liefert eine kristallklare, rauschfreie Ausgabe und erreicht dabei eine natürlich klingende Sprachqualität. Das Modell unterstützt aktuell sowohl Englisch als auch Chinesisch.